Künstliche Intelligenz und die Frage nach Erklärbarkeit
10. Juni 2019
KI
Müssen wir unsere Modelle verstehen, um ihnen zu vertrauen?

Die Entwicklung von künstlicher Intelligenz und neuronalen Netzen oder Netzwerken hat einerseits die Informatik stark beeinflusst, andererseits aber auch den Bereich der Neurowissenschaften in den Blickpunkt gerückt. Das Konzept von künstlichen neuronalen Netzwerken ist durch die Funktionsweise von Neuronen inspiriert, da sie entwickelt wurden, um rudimentär nachzubilden, wie Neuronen Informationen aufnehmen und verarbeiten.
Als Student der Neurowissenschaften fühlte ich mich zunächst zu neuronalen Netzen hingezogen, weil ich mit Hilfe von Computermodellen unsere eigene Kognition besser verstehen wollte. Die grundlegenden qualitativen Unterschiede zwischen menschlicher und künstlicher Intelligenz machen es für uns jedoch sehr schwer, den Entscheidungsfindungsprozess eines Modells in menschlicher Hinsicht zu verstehen.
Die derzeit eingesetzte künstliche Intelligenz funktioniert wie eine "Black Box" - wir können die Genauigkeit an einem Testsatz bestimmen und unser Modell anschließend mit einem gewissen Vertrauen in dessen Präzision auf neue Daten anwenden, aber im Zweifelsfall würden wir uns schwer tun, die Entscheidung eines Modells in einzelnen Fällen tatsächlich nachzuvollziehen. Als Antwort darauf ist in der Forschung der Bereich der erklärbaren KI (XAI) entstanden, der darauf abzielt, Techniken zu entwickeln, bei denen der Prozess, der zum Ergebnis eines Modells führt, von Menschen verstanden werden kann. Hierbei handelt es sich um eine anspruchsvolle Aufgabe, bei der es gilt viele Hürden zu überwinden. Dieser Umstand wirft wiederum die Diskussion auf, ob die Möglichkeit der Interpretation aus praktischer Sicht wirklich notwendig ist. Diese Frage stellt sich umso dringlicher, da hochentwickelte maschinelle Lernsysteme immer beliebter werden und nicht mehr nur von Tech-Unternehmen wie Google oder Facebook genutzt werden. Kleine bis mittelgroße Unternehmen automatisieren bestimmte Abläufe innerhalb ihrer Systeme, was zu einer groß angelegten Automatisierung von Entscheidungen, die wesentlich mehr Gewicht haben, bis hin zur autonomen Steuerung führen wird. Technologietrends in Unternehmen geben in der Regel einen guten Ausblick auf bevorstehende Veränderungen in Institutionen und Regierungen, innerhalb welcher die Übernahme von KI zunehmend folgen wird. Vor diesem Hintergrund wird die Diskussion über konzeptionelle Fragen, wie die hinsichtlich der Erklärbarkeit, immer dringlicher.
Wir werden uns zunächst drei Beispiele akademischer Ansätze genauer ansehen, die darauf abzielen, das Thema Erklärbarkeit aus verschiedenen Blickwinkeln zu betrachten. Anschließend werden wir das Thema konzeptionell betrachten und diskutieren, ob Interpretierbarkeit in der Praxis tatsächlich notwendig ist. (Spoiler-Alarm: Es kommt darauf an.)

Akademische Arbeit zum Thema Interpretierbarkeit
Transparente, bzw. erklärbare Künstliche Intelligenz bezieht sich auf Techniken in der KI, bei denen der Prozess, der zu einem Ergebnis führt, von Menschen verstanden werden kann. Sie steht im Gegensatz zu den "Black Box"-Implementierungen, bei denen man nicht erklären kann, warum das Modell zu einer bestimmten Entscheidung kommt. Einfach ausgedrückt:
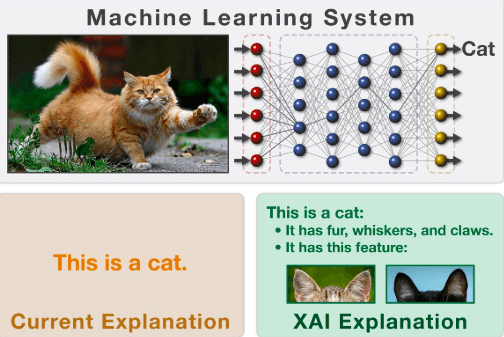
Die Idee, Modelle zu entwickeln, die von Menschen verstanden werden können, ist fast so alt wie die künstliche Intelligenz selbst. Mycin, ein Forschungsprototyp, der erklären konnte, welche seiner handcodierten Regeln zu einer Diagnose in einem bestimmten Fall beitrugen, stammt aus den 1970er Jahren. Dieses auf künstlicher Intelligenz basierende Expertensystem wurde an der Universität Stanford entwickelt, um Bakterien zu identifizieren, die bestimmte Infektionen verursachen, und um Antibiotika in einer auf das Gewicht der Person abgestimmten Dosierung zu empfehlen. Mycin arbeitete mit einem Wissensbestand von etwa 600 Regeln, und die Leistung dieses frühen Prototyps war im Vergleich zu der hohen Vorhersagekraft, die moderne Deep-Learning-Systeme in diagnostischen Kontexten aufweisen, ziemlich begrenzt. Daher mussten in den folgenden Jahren andere, effizientere Ansätze entwickelt werden.
Zurück zum biologischen Ursprung!
Ein klassisches Beispiel für biologisch inspirierte KI ist das Faltungsneuronale Netz (CNN). Die Eigenschaften von CNNs sind der grundlegenden Organisation unseres visuellen Systems nachempfunden. Im Jahr 1962 entdeckten Torsten Wiesel und David Hubel, dass unser primärer visueller Kortex aus zwei Arten von Neuronen aufgebaut ist. Einfache (S-)Zellen können als Randdetektoren an einer bestimmten Stelle der Netzhaut betrachtet werden. Erscheint der Rand an einer anderen Stelle in Ihrem Blickfeld, reagieren sie nicht. Komplexe (C-)Zellen haben eine größere räumliche Invarianz, d. h. sie reagieren auf Kanten mit ihrer bevorzugten Ausrichtung innerhalb eines großen rezeptiven Feldes. Komplexe Zellen erreichen dies, indem sie die Eingaben von mehreren einfachen Zellen mit derselben Ausrichtung zusammenfassen. Dieser Umstand wurde im Vorläufer des CNN, dem Neocognitron, nachgeahmt, welches ebenfalls aus "S-Zellen" und "C-Zellen" besteht, die durch nicht-überwachtes Lernen einfache Bilder erkennen.
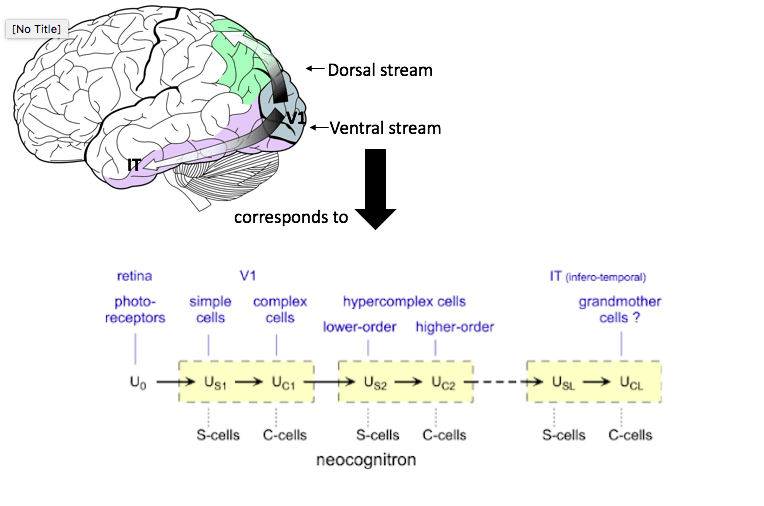
Je fortschrittlicher unsere Deep-Learning-Modelle jedoch werden, desto weiter entfernen wir uns von den ursprünglichen biologischen Parallelen. Man betrachte, wie unser ventraler visuelle Signalweg, bestehend aus dem Nucleus geniculatus lateralis (6 Neuronenschichten) und dem ventralen Strom (3 Neuronenschichten V1, V2, V4), uns in die Lage versetzt, extrem präzise zwischen verschiedenen Tieren zu unterscheiden. Diese Präzision ist vergleichbar oder sogar besser, als die einiger tiefer CNNs, die aus 100 Schichten bestehen. Neurowissenschaftler haben die Bedeutung der einzelnen neuronalen Schichten der visuellen Verarbeitung entschlüsselt. Der Versuch, zu verstehen, was jede Schicht eines KI-Modells in menschlicher Hinsicht kodiert, ist jedoch eine völlig neue Herausforderung. Ein Weg, dies zu erreichen, besteht darin, vergleichend zu untersuchen, warum das Gehirn mit scheinbar weniger Rechenschritten so genau arbeiten kann (und auf dieser Grundlage zu versuchen, Effizienzkonzepte in unsere KI-Modelle zu übertragen).
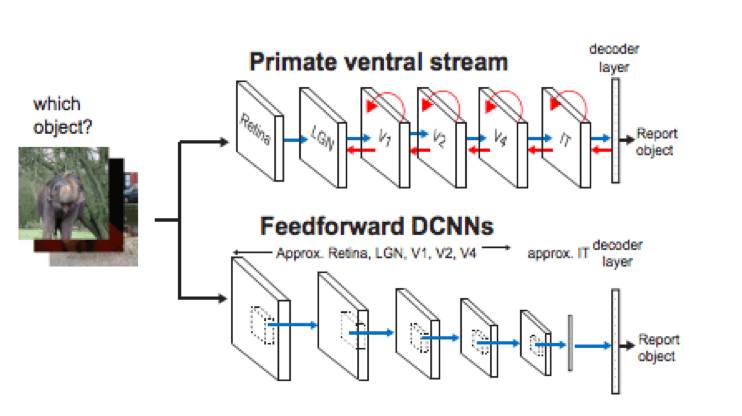
Im Labor von James Di Carlo am MIT arbeiten Wissenschaftler*innen an der Schnittstelle von Neurowissenschaften und Informatik und erforschen Möglichkeiten, neuronale Netze dem Gehirn anzugleichen. Letztes Jahr hat seine Gruppe gezeigt, wie wichtig wiederkehrende Schaltkreise für unsere Fähigkeit sind, Objekte zu erkennen. Sie verglichen tiefe Feedforward-CNNs mit Primaten (die wie wir wiederkehrende Rückkopplungsschaltungen verwenden) bei Aufgaben zur Objekterkennung. Die starke Leistung von nicht-wiederkehrenden CNNs bei Objekterkennungsaufgaben deutet darauf hin, dass solche Rückkopplungsprozesse für die Objekterkennung nicht unbedingt erforderlich sind. Durch den Vergleich von CNNs mit der visuellen Verarbeitung von Primaten ermittelte Di Carlo bestimmte "kritische" Bilder, die der Primat problemlos erkennen kann, während das CNN versagt. Bei derselben Gruppe von Bildern schneiden die tieferen CNNs besser ab. Was sagt uns das? a) Wiederkehrende Rückkopplungsschaltungen könnten ein Grund dafür sein, dass unser ventraler Strom deutlich weniger Neuronenschichten benötigt als moderne CNNs, sie sind also eine Anpassung an die Recheneffizienz, und b) während für die meisten Aufgaben der Objekterkennung diese wiederkehrenden Operationen nicht notwendig sind, könnte es einen kleinen Prozentsatz kritischer Situationen geben, in denen reine Feedforward-Systeme weiterhin versagen. Diese Erkenntnise sind zwar faszinierend für alle, die sich für Neurowissenschaften interessieren, zielen aber darauf ab, neuronale Netze zu nutzen, um das Gehirn zu verstehen, und nicht darauf, das Gehirn zu nutzen, um praktischere oder effizientere Modelle zu entwickeln.
Visualisierung neuronaler Netzwerke
Ein weiterer Ansatz besteht darin, Visualisierungstechniken zu entwickeln, die einen Einblick in das Innenleben der derzeit verwendeten Deep-Learning-Systeme gewähren. Dieser Ansatz ist besonders faszinierend, wenn es auf Generative Adversarial Networks (GANs) angewendet wird. GANs haben sowohl in der Forschung als auch in den populären Medien für Aufregung gesorgt, als viele Menschen zum ersten Mal von DeepFakes gehört haben. Dabei werden realistische Bilder oder Videosequenzen von Menschen erzeugen, oder Kunstwerke von KI generiert, die für über 400.000 Dollar verkauft werden. Bisher wurde KI zur Analyse, Verinnerlichung und Vorhersage eingesetzt, aber mit dem Aufkommen von GANs kann KI auch kreativ sein. Diese Technologie ist sehr leistungsfähig, aber wir verstehen nicht, wie ein GAN unsere visuelle Welt intern darstellt und was genau Ergebnisse bestimmt. Das Team von Antonia Torralba am MIT hat an der Beantwortung dieser Fragen gearbeitet. GANs scheinen Fakten über Objekte und Beziehungen zwischen Merkmalen zu lernen. Um ein Beispiel von Torralba zu zitieren: "Ein GAN lernt, dass eine Tür an einem Gebäude vorkommen kann, aber nicht an einem Baum. Wir wissen wenig darüber, wie ein GAN eine solche Struktur darstellt und wie Beziehungen zwischen Objekten dargestellt werden können". Um den "Entscheidungsfindungsprozess" eines GAN in menschlicher Hinsicht zu verstehen, schlägt Torralba die folgende Methode als allgemeinen Rahmen vor:
Erstens: Identifizierung von Gruppen interpretierbarer Einheiten, die mit Objektkonzepten in Beziehung stehen (z. B. Identifizierung von GAN-Einheiten, die Bäumen entsprechen). Zweitens: Identifizierung von Gruppen, die einen Objekttyp (z. B. Bäume) zum Verschwinden bringen. Drittens: Versuch, diese Objektkonzepte in neue Bilder einzufügen und Beobachtung, wie dieser Eingriff mit anderen Objekten im Bild interagiert. Betrachten wir dies anhand von GAN-generierten Bildern von Kirchen. Wir versuchen herauszufinden, welcher Teil des Modells die Objektklasse der Bäume erzeugt:
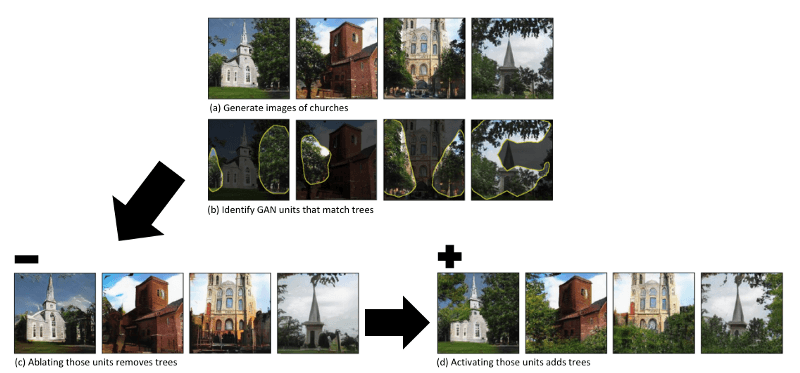
Zusammenfassend lässt sich sagen, dass wir durch die Identifizierung von Einheiten, die für die Generierung einer Objektklasse erforderlich sind, Teilen unseres GAN-Modells eine Bedeutung zuweisen können. Praktisch ist dies nützlich, wenn wir unser GAN auf kontrollierte Weise verbessern wollen (d.h. nicht nur durch Trial and Error oder langes Training). Im folgenden Beispiel haben wir unvollkommene GAN-generierte Bilder von Schlafzimmern mit Attributen, die das Bild stören. Durch die Identifizierung und Entfernung der Einheiten, die diese Attribute verursachen, werden bessere Ergebnisse erzielt.

Quantifizierung der Merkmalsbedeutung
Auf dem Gebiet der Modellvisualisierung konzentrieren sich die meisten Ansätze auf die Visualisierung spezifischer Bildmerkmale, welche einzelne CNN-Schichten lernen zu erkennen. Diese mühsame Aufgabe wird noch aufwändiger, wenn man sich der Herausforderung stellen muss, ein solches Interpretierbarkeitssystem für jedes weitere Modell neu aufzubauen. Eine Möglichkeit, dieses Problem anzugehen, besteht in der Entwicklung einheitlicher Ansätze (d. h. allgemeiner Interpretierbarkeitswerkzeuge, die auf verschiedene ML-Modelle angewendet werden können). Ein solcher einheitlicher Rahmen für die Interpretation von Modellvorhersagen wurde 2017 von Lundberg und Lee an der University of Washington geschaffen. Ihr Modell, SHAP¹, basiert auf Shapley-Werten, einer Technik, die in der Spieltheorie verwendet wird, um zu bestimmen, wie viel jeder Spieler in einem kooperativen Spiel zu dessen Erfolg beigetragen hat. In unserem Fall misst jeder SHAP-Wert, wie signifikant jedes Merkmal in unserem Modell zum vorhergesagten Output unseres Modells beiträgt. Dies führt weg von konkreten Erklärungen der "Rolle" einer Ebene (z. B. Kodierung von Kanten an einer bestimmten räumlichen Stelle) hin zu einem abstrakteren Konzept der Interpretierbarkeit, bei dem die Entscheidung an sich nicht verstanden wird, aber das Gewicht der einzelnen Komponenten, die zum Ergebnis beitragen, entschlüsselt werden kann. SHAP liefert derzeit das beste Maß für die Bedeutung von Merkmalen, allerdings mit einem enormen Rechenaufwand, der mit der Anzahl der eingegebenen Merkmale exponentiell ansteigt. Für die überwiegende Mehrheit der Probleme macht dies die Aussicht auf eine vollständige Implementierung unpraktisch.
Die beiden Forscher, die dieses Modell entwickelt haben, haben noch im selben Jahr ein ML-System mit dem Namen "Prescience" entwickelt, das verspricht, das Risiko einer Hypoxämie (abnorm niedriger Sauerstoffgehalt im Blut) in Echtzeit vorherzusagen und gleichzeitig eine Erklärung der Faktoren zu liefern, die zu dem ermittelten Risiko beitragen (z. B. BMI, Alter, Puls usw.). Dies könnte bei Operationen unter Narkose, bei denen viele schwankende Variablen überwacht werden müssen, äußerst nützlich sein. Obwohl das Entwicklerteam zu den ersten gehört, die ein hochpräzises Modell von beträchtlicher Komplexität mit interpretierbaren Erklärungen kombinieren, räumen die Autoren auch ein, dass ihr Vorschlag ein erster Versuch ist, der aufgrund mehrerer von ihnen beschriebener Mängel noch weit von einer praktischen Umsetzung entfernt ist. Die Herausforderung, genaue und komplexe KI-Systeme zu schaffen, die auch intuitive Erklärungen für ihren Entscheidungsprozess liefern, wird auf absehbare Zeit eine Herausforderung bleiben, wobei in der Forschung derzeit viele vielversprechende Ansätze vorgeschlagen werden.

Der Zielkonflikt zwischen Vorhersagekraft und Interpretierbarkeit ist schwieriger zu überwinden, als man vielleicht denkt: Man bedenke, dass der eigentliche Zweck der Entwicklung komplexer Modelle manchmal darin besteht, komplexe Hypothesen auszudrücken, die über dem menschlichen Verständnis liegen. Wenn wir Systeme anstreben, die in der Lage sind, aus einer größeren Anzahl von Merkmalen zu lernen und Vorhersagen zu treffen, als es ein Mensch könnte, müssen wir die Option in Betracht ziehen, dass es konzeptionell nicht möglich ist, diese hochdimensionalen Vorhersagen mit menschlichen Begriffen zu erklären. Das oben beschriebene "Prescience"-Modell visualisiert etwa 15 Variablen, die die Entscheidung des Modells beeinflusst haben, aber was ist, wenn das Krankheitsvorhersagemodell eine Million Merkmale hat und die Evidenz für eine Diagnoseentscheidung über diese Merkmale verteilt ist? Mit einem Interpretierbarkeitsrahmen, der einige herausragende Merkmale erklärt, muss das Modell selbst entweder auf diese Merkmale beschränkt werden, oder unsere Visualisierung würde das Verhalten des Modells nicht wahrheitsgetreu beschreiben und somit seinen Anspruch auf "Transparenz" negieren.
Praktische Bewertung
Inwieweit sind diese Ansätze von praktischem Interesse? Bei der Beantwortung der Frage, ob sich die Bemühungen um Interpretierbarkeit lohnen, neigen die meisten Kommentare zu einer klaren Haltung: Ja oder Nein. Befürworter des erklärbaren maschinellen Lernens argumentieren, dass wir immer verstehen müssen, wie unsere Werkzeuge funktionieren, bevor wir sie einsetzen. Die Zusammenarbeit, in diesem Fall zwischen Algorithmen und Menschen, hängt von Vertrauen ab, und Vertrauen erfordert wohl eine Grundlage, z. B. Verständnis. Wenn die Menschen algorithmische Vorschriften akzeptieren sollen, müssen sie ihnen vertrauen und sie daher verstehen. Dieses Argument allein ist meiner Meinung nach fragwürdig. Andrew Ng hat bekanntlich gesagt, dass KI die neue Elektrizität ist, in dem Sinne, dass Elektrizität jede Industrie 100 Jahre lang unwiderruflich verändert hat, bevor sie vollständig verstanden wurde, und dass KI das Gleiche tun wird. Noch bevor die Wissenschaft hinter elektrischen Phänomenen vollständig erklärbar war, konnten Risiken erkannt und eine sichere Nutzung implementiert werden. In ähnlicher Weise könnte man argumentieren, dass bei der KI der Schwerpunkt derzeit darauf liegen sollte, zu vermitteln, wie diese neuen Technologien im weiteren Sinne zu unserem Vorteil genutzt werden können und wo die Grenzen und (rationalen) Gefahren liegen. Diese Antwort ist jedoch ebenso verallgemeinernd, und es wäre kurzsichtig, die Interpretierbarkeit einfach als praktisches Problem abzutun. Wie KI eingesetzt werden kann, ist in hohem Maße kontextabhängig - zum einen müssen wir zwischen Branchen und auch innerhalb von Sektoren zwischen spezifischen Anwendungsfällen und der Schwere der Vorhersagen/ihrer Folgen unterscheiden.
Wenn man über das Gesundheitswesen spricht, würde man intuitiv annehmen, dass die Interpretierbarkeit durchgängig im Vordergrund stehen sollte. Die erste Ausnahme hiervon ist die Nutzung von KI zur Unterstützung operativer Eingriffe. Einrichtungen des Gesundheitswesens generieren und erfassen enorme Mengen an strukturierten und unstrukturierten Daten, z. B. in Form von Patientenakten, Personalmustern, Verweildauer in Krankenhäusern, etc.. Ohne allzu große Bedenken hinsichtlich der Interpretierbarkeit können wir hochpräzise Modelle einsetzen, um die Patientenversorgung und -betreuung zu optimieren oder die Nutzung elektronischer Patientenakten zu erleichtern. Für die Entwicklung von klinischen Entscheidungssystemen gelten ganz andere Kriterien. Wir wissen, dass Deep-Learning-Modelle bei der Erkennung einiger Krebsarten kritische Muster mit höherer Genauigkeit erkennen können als erfahrene Ärzte.
In vielen Fällen steht bei diesen Entscheidungen jedoch viel auf dem Spiel, und während ein Arzt seine Entscheidung erklären kann, indem er die ausschlaggebenden Faktoren nennt, die seine Diagnose beeinflusst haben, kann ein Deep-Learning-Modell nicht auf dieselbe Weise abgefragt werden - zum einen, weil der Grund für seine höhere Genauigkeit gerade in der Fähigkeit liegt, mehr Faktoren und komplexe Wechselwirkungen zu berücksichtigen, als sie von Menschen verstanden werden können. Weitergedacht würde dies auch noch nie dagewesene rechtliche Fragen rund um die Verantwortung aufwerfen - derartige Debatten wurden bereits im Zusammenhang mit autonomen Fahren geführt. Die Forderung nach Erklärbarkeit könnte durchaus ein Haupthindernis für die automatisierte Erkennung von Krankheiten bleiben. Ein Bereich, in dem der Bedarf an erklärbarer KI weniger eindeutig ist, ist die medizinische Bildgebung. Wie in diesem Artikel beschrieben, ist eine vielversprechende Anwendung für Deep Learning die Beschleunigung von MRT-Scans durch intelligente Rekonstruktion von lückenhaften Bildern. Dies unterscheidet sich von der automatisierten Diagnose, da das Modell darauf trainiert ist, Details zu schärfen und zu rekonstruieren, nicht aber Strukturen zu erkennen. Die Genauigkeit des Rekonstruktionsalgorithmus kann getestet werden, indem Bilder mit geringer Qualität erstellt werden, die als Eingabe für das Modell dienen, und dann die Ausgabe mit dem Originalbild verglichen wird. Es besteht jedoch die Sorge, dass der Algorithmus im Laufe der Zeit Verzerrungen entwickeln könnte, die von der Verteilung der Eingaben abhängen, was ohne Einblick in das Innenleben des Modells schwer zu erkennen ist.
Zusammenfassend...
Erklärbarkeit ist wichtig, aber nicht immer unerlässlich. Wir müssen ein KI-Modell in der Regel nicht unbedingt verstehen, um es einzusetzen, aber es sollte das langfristige Ziel sein, damit die Einbeziehung multidimensionaler neuronaler Netze auch in sensiblen Entscheidungsprozessen ermöglicht werden kann. Alles läuft auf einen kontextabhängigen Kompromiss hinaus. Die höchste Genauigkeit für große moderne Datensätze wird oft durch komplexe Modelle erreicht, die selbst für Experten schwer zu interpretieren sind, was ein Spannungsverhältnis zwischen Genauigkeit und Interpretierbarkeit schafft. In jedem Bereich müssen wir den Wert von Genauigkeit und Automatisierung mit dem Bedarf an Einblick in den Entscheidungsprozess vergleichen.
Während das Bestreben, beides miteinander zu verbinden, in naher Zukunft noch Gegenstand der Forschung sein wird, müssen wir die Frage des Vertrauens und der Transparenz im Kontext einer bestimmten Aufgabe berücksichtigen und Systeme entwickeln, die auf diese Anforderungen zugeschnitten sind und es uns dennoch ermöglichen, von der Vorhersagekraft der KI zu profitieren.
[1] Weitere Erklärungen
Wir bei Luminovo wissen um die Nuancen individueller Geschäftsprobleme und die unterschiedlichen Anforderungen, die sie mit sich bringen. Mit der Aussicht auf den zunehmenden Einsatz von KI in sensiblen Entscheidungsprozessen haben wir uns in unserer internen Forschung dem Aufbau von Interpretationsrahmen für tiefe neuronale Netze durch fortschrittliche Visualisierung gewidmet. Während solche Modelle, die auf dem neuesten Stand der Forschung beruhen, einen gewissen Einblick in die interne Funktionsweise von KI-basierten Systemen gewähren, liegt ein vollständiger Einblick in den Entscheidungsprozess eines Modells noch in weiter Ferne. Daher kombiniert unsere praktische Lösung menschliches Expertenwissen, das nach wie vor unübertroffen ist, wenn es darum geht, kritische Randfälle, die von der Norm abweichen, zu entschlüsseln, mit einer sich ständig verbessernden künstlichen Intelligenz innerhalb eines Hybridsystems. Indem wir die Kommunikation durch Feedback zwischen Nutzer und Modell einbeziehen, nutzen wir die gegensätzlichen Stärken, die menschliche und künstliche Intelligenz auszeichnen. Dieses Format verbindet das Bedürfnis nach Transparenz mit praktischer Realisierbarkeit.
Dank an Sebastian Schaal.


