New Perspectives on Transfer Learning: Structuring ML Concepts
June 2, 2020
This last installment introduces Hybrid Processing and maps it together with Active Learning and Transductive & Inductive Semi-Supervised Learning in a novel framework.

Note: This article was first published on Towards Data Science Medium.
In the column “Structuring Machine Learning Concepts”, I am trying to take concepts from the Machine Learning (ML) space and cast them into new, potentially unusual frameworks to provide novel perspectives. The content is meant for people in the data science community, as well as tech-savvy individuals who are interested in the field of ML.
Introduction
The last installment of “Structuring Machine Learning Concepts” was dedicated to introducing Hybrid Processing and mapping it together with Active Learning and Transductive & Inductive Semi-Supervised Learning in a novel framework.
The trigger for writing this piece was the ubiquity of Transfer Learning these days, branching out in many directions. It comes in various shapes and colors, but the methodology lacks a higher-level framing. Let’s expand on that.
The Framework: Eight Routes of Transfer Learning
Transfer Learning (TL) has probably been one of the most important developments in Deep Learning to make it applicable for real-world applications. Many might remember the “ImageNet moment” when AlexNet crushed the ImageNet competition and made neural networks the standard for Computer Vision challenges.
However, there was one problem — you needed a lot of data for this to work, which was often not available.
The solution to this came with the introduction of TL. This allowed us to take a Convolutional Neural Network (CNN) pre-trained on ImageNet, freeze the first layers, and only re-train its head on a smaller dataset, bringing CNNs into industry mass adoption.
In 2018, this “ImageNet moment” finally arrived for Natural Language Processing (NLP). For the first time, we moved from re-using static word-embeddings to sharing complete language models, which have shown a remarkable capacity for capturing a range of linguistic information. Within that development, Sebastian Ruder published his thesis on Neural TL for NLP, which already mapped a tree-breakdown of four different concepts in TL.
Mapping dimensions
This got me thinking: what are the different means of using insights of one or two datasets to learn one or many tasks. These are the dimension I could think of:
Task: Are we trying to teach our network the same task in a pre-training and fine-tuning step, or are we using the knowledge of the first task to leverage it for a different second one? (e.g., pre-training an “animal classifier” and fine-tuning the model as a “dog breed classifier” vs. using the backbone of an “animal classification” network to train a “fluffy ears object detector”)
Domain: Do we have datasets from the same domain or different ones? (e.g., both datasets are color images taking “in the wild” vs. one being gray-scale x-ray images)
Order: Are we learning the tasks simultaneously or one after another? (e.g., we are computing the loss on all tasks jointly and use it for training vs. finishing the first training, porting the weights of the network, and then starting the second training)
I also considered adding “Importance” to be able to include auxiliary tasks, but let’s not complicate things too much. Thereby, I ended up with similar dimensions as Ruder has also used for NLP. Let’s map out all eight combinations, resulting from the three binary dimensions.
Lightweight definitions
I will make some opinionated decisions about the terms, which are not backed by extensive literature — bear with me.
Task Fine-Tuning: This applies when we are pre-training a model to then fine-tune it to another dataset in the same domain with the same task, which is even more specific to our problem (e.g., using a pre-trained ImageNet classification model (INCM) and then fine-tuning it to a dog-breed-classifier).
Domain Adaptation: We are working on the same task, but are transferring our model into a new domain that is given by another dataset at hand (e.g., taking a pre-trained INCM and fine-tuning it on classifying healthy and sick patients based on x-rays).
Task Adaptation: Taking the knowledge of a pre-trained model (i.e., its intermediate outputs as embeddings) to train it on a different task (e.g., using the backbone of an INCM as a feature extractor and adding a second network to perform object detection).
Modality Transfer: It might make sense to use a network pre-trained on e.g. images, even if the domain and task differ. At least, the network has already picked up on the modality (e.g., using the INCM backbone to run object detection on breast carcinoma in x-rays).
Dataset Merging: If you want to train on two datasets from the same domain simultaneously on the same task, feel free to merge them (e.g., adding images scraped from Instagram to the ImageNet dataset to train an even better classifier).
Weight Sharing: Even if you are training two problems at the same time, it might make sense to share some intermediate weights (e.g., using the OCR-generated text and the raw image of a PDF document to feed into a joined intermediate representation, to classify the context of the page and whether it is the start of a new document).
Multi-Task Learning: One of the most popular instances is Tesla’s large vision network, where a shared backbone is jointly trained on multiple tasks at once (e.g., using the same footage of the cameras in a Tesla to run object detection and road marking segmentation in parallel).
Parallel Training: And finally, if you have two different problems (domain and task) and you want to train them at the same time, just do it in parallel (e.g., performing content moderation and e-mail classification for the same client).
The Extended 2x2x2 Matrix
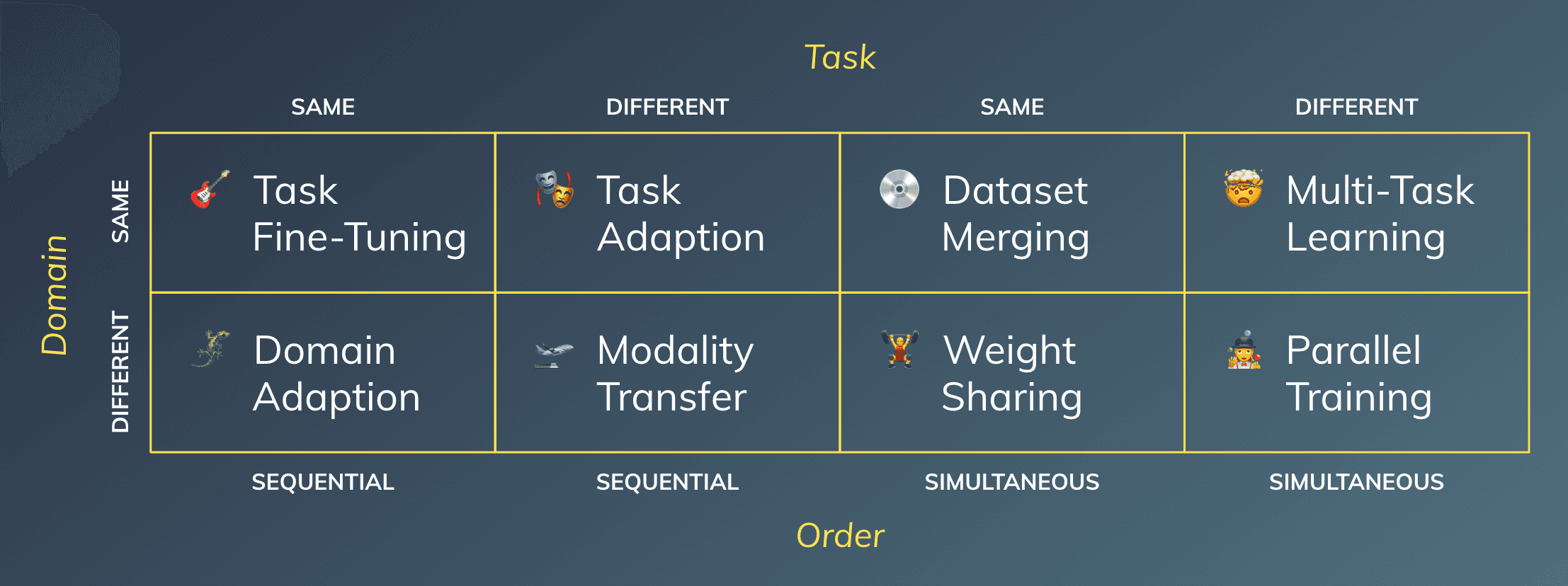
Using the dimensions Task, Domain, and Order, we end up with this 2x2x2 matrix, mapping out the concepts introduced before. For a 2D visualization, I put two dimensions on the x-axis and doubled the binary entries, ending up with 8 distinct cells (e.g., the upper left one would be same Domain, same Task, and sequential Order).
Closing
In this post, we have used the dimensions of Task, Domain, and Order to structure the ways we can perform TL. I enjoyed indulging in my consulting past by expanding them to a larger matrix, getting me to think about completely new scenarios while trying to fill the empty fields. This has led to some rather obvious cases of (e.g., “Dataset Merging” and “Parallel Training”) all the way to some known procedures that did not have a commonly used name yet (e.g., “Task Fine-Tuning”).
If you have any other unconventional mappings, thoughts on the matter, or are interested in our work at Luminovo, I would love to hear from you. You can leave a comment or reach me on Linkedin.
Stay tuned for the next articles.
Thanks to Lukas Krumholz and Aljoscha von Bismarck.


