The Four “Pure” Learning Styles in Machine Learning - Structuring ML Concepts
May 20, 2020
People are starting to realize that some techniques that were previously regarded as Unsupervised Learning should more aptly be named Self-Supervised Learning. Let’s expand on that.

Note: This article was first published on Towards Data Science Medium.
In the column “Structuring Machine Learning Concepts”, I am trying to take concepts from the Machine Learning (ML) space and cast them into new, potentially unusual frameworks to provide novel perspectives. The content is meant for people in the data science community, as well as tech-savvy individuals who are interested in the field of ML.
Introduction
Back in 2015 when I started picking up ML at Stanford, the concepts and definitions around it were fairly structured and easy to map out. With the rapid growth of Deep Learning in recent years, the variety of terms and concepts used has increased immensely. This can leave newcomers to the field, who wish to learn more about the subject, frustrated and confused.
The trigger for writing this installment of “Structuring Machine Learning Concepts” was the concept confusion that recent breakthroughs in Natural Language Processing (NLP) and Computer Vision have brought to the table. People are starting to realize that some techniques that were previously regarded as Unsupervised Learning should more aptly be named Self-Supervised Learning. Let’s expand on that.
Supervised, Self-Supervised, Unsupervised, and Reinforcement Learning
When people talk about the different forms of Machine Learning, they usually refer to Supervised Learning (SL), Unsupervised Learning (UnSL), and Reinforcement Learning (RL) as the three learning styles. Sometimes, we add Semi-Supervised Learning (SemiSL) to the mix, combining elements of SL and UnSL. In 2018, a new breed of NLP algorithms started to gain popularity, leading to the famous researcher Yann LeCun to coin the concept of Self-Supervised Learning (SelfSL) in 2019.
Lightweight definitions — the original four learning styles
SL: We are using a dataset, where we want to predict a specific target, given other features (e.g., a table) or raw input (e.g., an image). This could take the form of classification, (predicting a categorical value — “Is this a cat or a dog?”) or regression (predicting a numerical value — “How cat-like is this image?”)
UnSL: Now assume we only have the raw input (e.g., just some user data in tables with no target or a lot of images with no information associated with them). Our goal is to look for previously undetected patterns, e.g., clusters or structures, that give new insights and can guide our decision-making.
RL: Normally stands out from the pack, since it is not working on a pre-collected dataset but trying to master a task in an environment by taking actions and observing the reward. Until we explicitly state a reward function to incentivize the agent to behave accordingly, it has no idea what to do in the given environment. Video games are a perfect example: the player (agent) tries to maximize her score (reward) by interacting with the video game (environment).
SemiSL: Often added as a fourth learning style, which works on one dataset with specified targets and on another, often larger one, without targets. The goal is to infer the labels of unlabeled data points with the help of knowledge from the labeled data points, thereby building the best possible model to map inputs to the targets. Think about you having access to data points of a manufacturing machine, which can be grouped into two clusters. From the labeled dataset you know, that all the unknown data points that are associated with a failure fall in cluster “A” and all normal states land in cluster “B”; hence the assumption that all points in “A” are critical and those on “B” are not.
Dropping SemiSL for SelfSL
There are two things worth mentioning about these four learning styles:
As already hinted at, most of the UnSL being done in Computer Vision and NLP recently is better described as SelfSL. This new learning style is not supervised using a given ground-truth, but using information contained in the training data itself. However, there are still parts of the “old family” of UnSL algorithms, which are truly unsupervised, that use some metric of closeness or proximity between data points to decide what is a good fit (and guide our loss function).
Also, if you think about it, SemiSL should not be a part of these “pure” learning styles. One, it is rather a mix of two “pure” learning styles and two, its basic setup involves having two different datasets, one labeled and one unlabeled. Therefore, we will save SemiSL for the next post of the “Structuring Machine Learning Concepts” series, where we will talk in more detail about processing unlabeled data.
Lightweight definitions — a new split
SelfSL: We only have raw input (e.g., images or lots of text) and we want to capture the implicit information it contains. We do so by using (parts of) the raw input as a target. In an Autoencoder, we are using the “reconstruction loss”, i.e., comparing the decoded image with the original input. In large scale language models, we are “hiding” parts of the sentence to then use it as a prediction target, only using the surrounding words (e.g., Marry ____ her husband → [loves]).
UnSL (revisited): In contrast to SelfSL, we are not measuring the “fit” of our model based on some “hidden” ground-truth but the implicit proximity of the “transformed input”, i.e., the distance of data points in the feature space. We can influence how this fit is defined, e.g., if we expect the clusters to be dense or linked continuously, but the proximity objective stays untouched. An example would be clustering users by behavior on a specific platform and using the assigned clusters to guide your marketing strategies.
The 2x2 Matrix
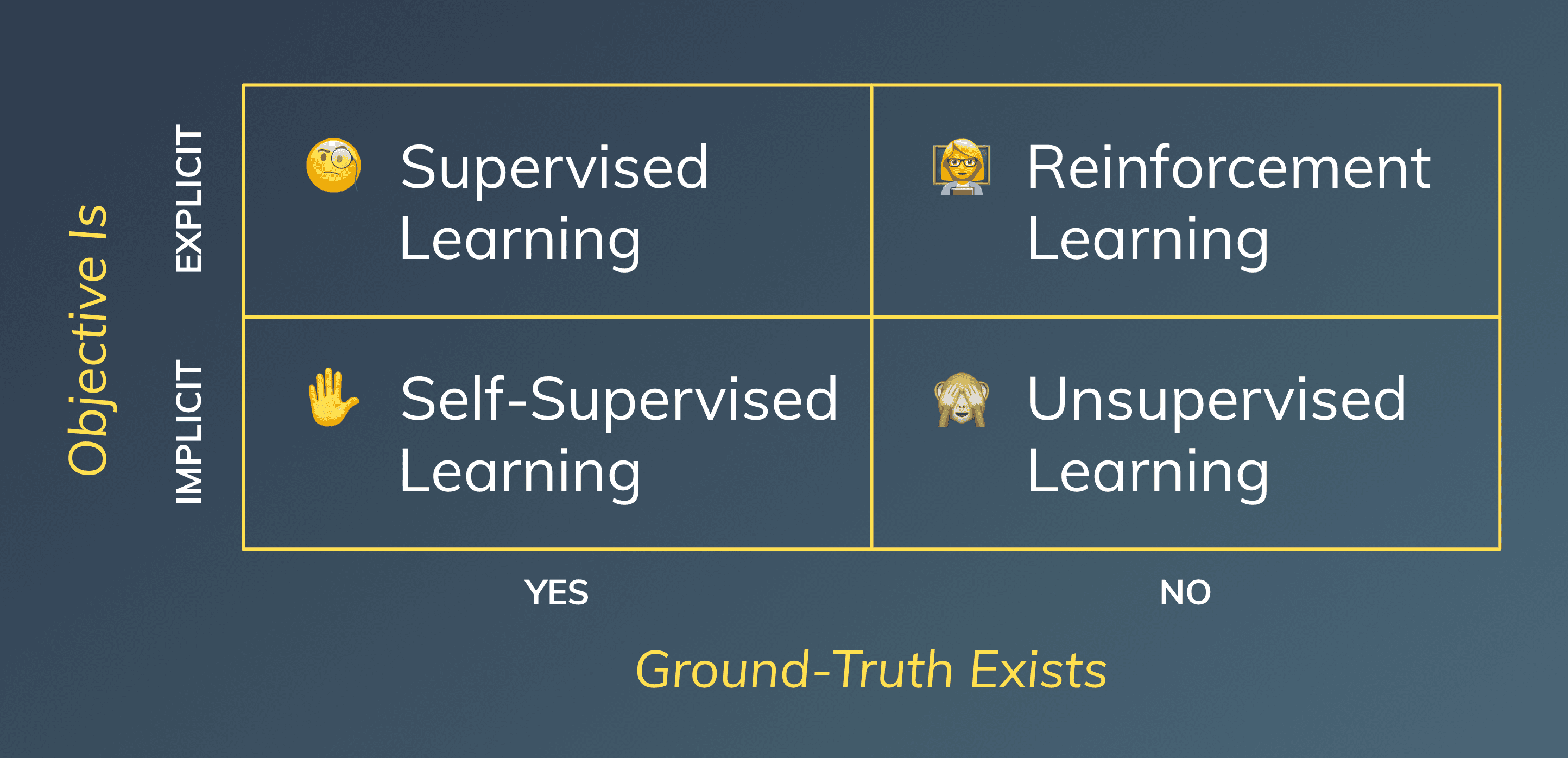
Iam proposing a simple 2x2 matrix, which maps SL, UnSL, SelfSL, & RL onto two axes, answering the following questions:
Does the ground-truth exist?
Yes
For SL and SelfSL, there is a ground-truth we are using to build our loss functions and metrics. Be it the “cat” label on an image for SL, driving the “categorical cross-entropy loss” and the “accuracy”, or the “hidden” word in a sentence (Marry [loves] her husband) for SelfSL, where we use “negative log-likelihood” as a loss and measure “perplexity”.
No
For UnSL and RL, there is no such ground-truth. We have measures that describe “good fit” or “desired behavior”, but nothing similar to “accuracy”. In “k-means clustering” of UnSL for example, we can measure the “average distance to the cluster mean”, and in RL, we are trying to maximize the “cumulative reward” we are receiving from the environment.
Is the objective explicitly or implicitly given?
Explicit
In SL and RL, we have an explicit choice of what we want to get out of the data or our agent. For SL, it is our choice to turn a “cats and dogs breeds classification” problem into a simple “cats and dogs classification” problem, by re-assigning the labels. When using RL for mastering multi-player computer games, we can choose to incentivize our agent to act as a team player by rewarding the actions taken for the benefit of the group or to act as an egoist by solely rewarding individual actions.
Implicit
However, we cannot extrinsically dictate the nature of an image or language in SelfSL. We can surely change some details, but the “reconstruction loss” will always compare two images, and for language models, we will always come up with learning tasks looking at the sentences themselves. With classical UnSL, we are implicitly stuck with finding data points that are close to each other, e.g., two users leaving behind similar behavior data on social media platforms.
Closing
Inthis post, we have redefined the “pure” learning styles in ML by separating UnSL and SelfSL and leaving SemiSL out of the equation. This brings us to the four concepts of SL, UnSL, SelfSL, and RL, which we can arrange in a simple framework (full disclosure: I did work in consulting for a while). The 2x2 matrix structures them according to whether a ground-truth exists and whether the objective is explicitly or implicitly given.
If you have any other unconventional mappings, thoughts on the matter, or are interested in our work at Luminovo, I would love to hear from you. You can leave a comment or reach me on Linkedin.
Stay tuned for the next articles.


