Processing Unlabeled Data in Machine Learning - Structuring ML Concepts
May 25, 2020
In this post, I finally found personal closure on the topic of how AL translates to some real-world scenario and introduce Hybrid Processing as a new paradigm.

Note: This article was first published on Towards Data Science Medium.
In the column “Structuring Machine Learning Concepts”, I am trying to take concepts from the Machine Learning (ML) space and cast them into new, potentially unusual frameworks to provide novel perspectives. The content is meant for people in the data science community, as well as tech-savvy individuals who are interested in the field of ML.
Introduction
The last installment of “Structuring Machine Learning Concepts” was dedicated to presenting a new framework to map Supervised, Self-Supervised, Unsupervised, and Reinforcement Learning. I claim that those are the actual “pure” learning styles we should consider in ML.
The trigger for writing this piece was my company’s work in automating human labeling tasks in real-world scenarios. I was always eager to match what we are trying to do with the lingo of research but was never truly satisfied with the concepts presented there. Let’s expand on that.
Hybrid Processing, Active Learning, and Transductive & Inductive Semi-Supervised Learning
The concept of Hybrid Processing
When I talk about human labeling tasks, I am referring to business processes where humans are completing a SL problem. This can be content moderation on images in media companies (e.g., deciding between “safe for publishing” and “not safe for publishing”), routing incoming emails and documents through the organization (“department 1”, “department 2”, …), or extracting information from incoming PDF orders (“name”, “IBAN”, ...). With many of them, there is often a human-only process in place today, which could benefit from automation.
Ideally, you don’t try to shoot for a 1-to-1 replacement, but you start automating the obvious cases using algorithms and leave the rest to the human. At my company Luminovo, we have been thinking a lot about how to structure an ML system that truly lives up to the promise of continuous learning when used to automate a human-only SL process step-by-step. We called it Hybrid Processing since we are using a human-AI hybrid to follow the goal of processing data.
We normally start either with zero knowledge or with a pre-trained base model. In the beginning, our model is not confident enough to automate anything, so all the incoming data points are labeled by the human. Thereby, she not only completes the task but also provides feedback to the model in the form of a new input-output pair, which can be used for re-training.
The story with two datasets & a human-in-the-loop
When explaining this concept to friends in the ML community, it is often compared to Active Learning (AL). Putting aside the “online nature” of most automation tasks (as opposed to consuming data in batches in a normal AL setup), I never completely warmed up to the comparison since the overarching goal of AL is to create “as good of a model” as possible with “as little data” as possible. Hybrid Processing, on the other hand, does not care about the quality of the model, at least not as its primary objective. The goal instead is to self-label as many data points as possible and only send the uncertain ones to the human.
When trying to generalize this, I realized that the whole concept of Semi-Supervised Learning (SemiSL), as explained in the last part of the “Structuring Machine Learning Concepts” series, fits in quite nicely with those considerations. Remember, in SemiSL we are trying to combine an (often small) amount of labeled data with a large amount of unlabeled data during training. This is similar to what we want to achieve in AL and Hybrid Processing, however, we are missing an important element: the human-in-the-loop. For SemiSL, we do not have access to an “oracle” but are stuck with the labeled data we are given. Also, this process is not “online”, meaning the concept of time is not a key driver.
When looking into the SemiSL theory, I did find exactly the split I was searching for: SemiSL can be either transductive or inductive. For Transductive SemiSL, the goal is to infer the correct labels for the unlabeled data; for Inductive SemiSL, we want to infer the correct mapping from X to Y, or put differently: build the best model we can.
Lightweight definitions
Hybrid Processing: An ML model is continuously trained on the data procured by humans, following their normal labeling routine. With every improved version of the model, its confidence thresholds are re-calibrated, allowing for automatic processing of more and more data points over time.
AL: We are trying to improve an underlying ML model by continuously deciding how we should use our “labeling budget” with the human-in-the-loop, e.g., paying a trained doctor to diagnose/classify some x-ray scans. There are various forms of AL, differentiating on which parts of the unlabeled data we can access at a given time (scenarios) and how we are deciding on which instances to label (query strategy).
Transductive SemiSL: We aim to provide labels to the unlabeled dataset with the help of the few labels we have in the first dataset. Plus, we expect at least one of three assumptions to hold: continuity (close points share a label), cluster (clustered points share a label), and manifold (points that lie on a lower-dimensional plane share a label).
Inductive SemiSL: The general assumptions of SemiSL I just explained still hold, but we are now trying to infer the true input-output relationship of the data and the labels, without caring about assigning labels to specific, potentially noisy data points. Thereby, our model cares not just about the unlabeled examples at hand, but also about the new ones to come.
The 2x2 Matrix
2x2 Matrix for Hybrid Processing, AL, and Transductive & Inductive SemiSL. Created by Author.
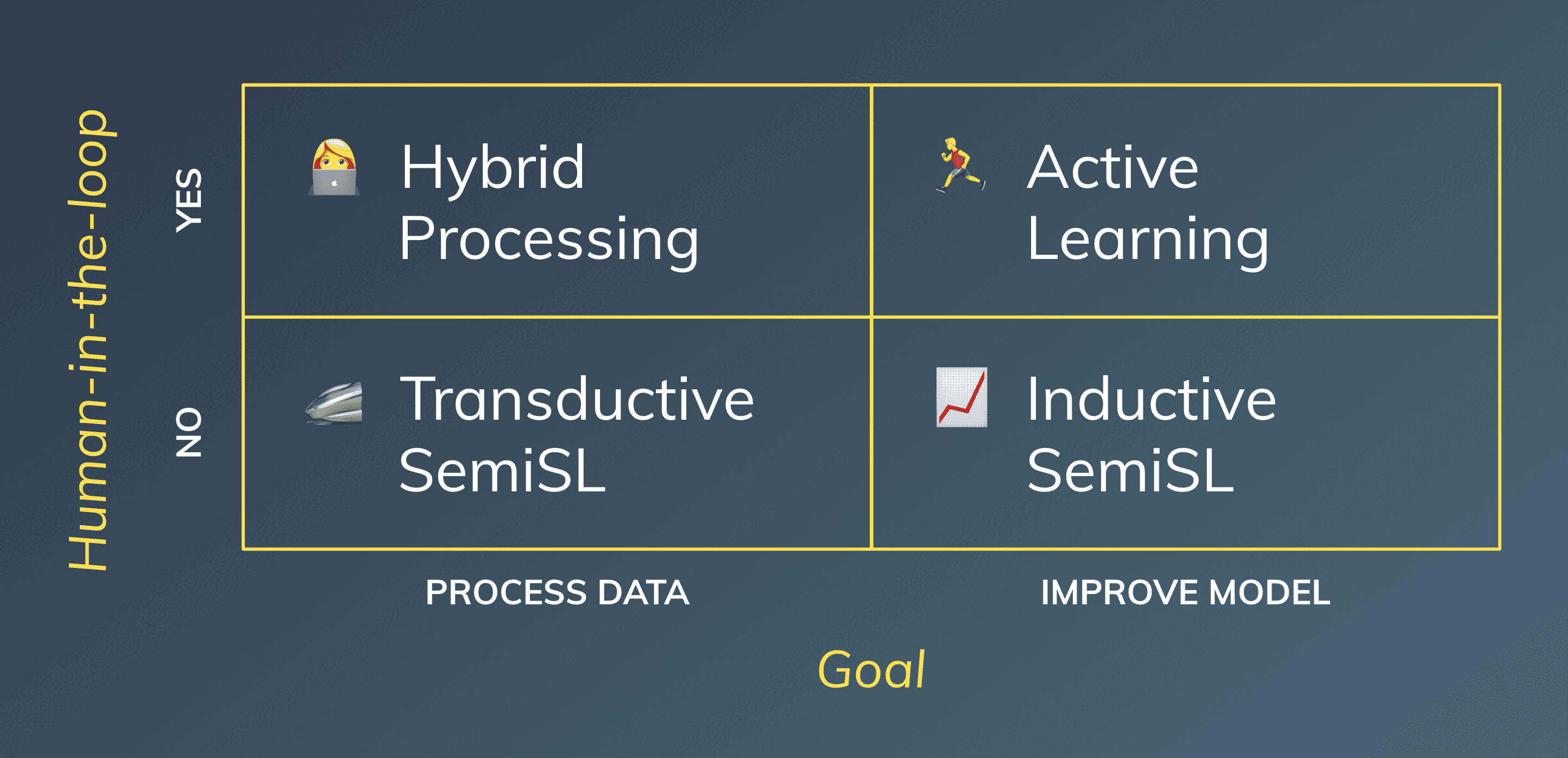
Once again, I am proposing a simple 2x2 matrix with the following dimensions:
Goal: process data or improve the model?
Process data
Is it the ultimate goal to process data, i.e., perform transduction, and assign labels to all my unlabeled points?
Improve model
Or do we only care about improving the model, i.e., finding the true mapping from input to output?
Is there a human-in-the-loop?
Yes
Do we have access to an “oracle” that can provide us with labels?
No
Or are we left with the information we have already gathered?
There is a lot more you can write about all of these quadrants, especially about AL and its scenarios and query strategies. I’ll leave this for another blog post.
Closing
Inthis post, I finally found personal closure on the topic of how AL translates to some real-world scenarios. I introduced Hybrid Processing as a new paradigm where it is our goal to solve human labeling tasks as efficiently as possible. Together with the known concepts of AL and Transductive & Inductive SemiSL, we were able to set up a 2x2 matrix with the dimensions asking if we aim to improve the underlying model and if we have access to a human-in-the-loop.
If you have any other unconventional mappings, thoughts on the matter, or are interested in our work at Luminovo, I would love to hear from you. You can leave a comment or reach me on Linkedin.
Stay tuned for the next article.
Thanks to Timon Ruban, Pranay Modukuru, Lukas Krumholz, and Aljoscha von Bismarck.


